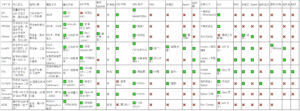
KAT-V1模型共有40B和200B两个版本。在自动思考模式下,40B版本的性能可追平今年5月发布的新版DeepSeek-R1(参数量为6850亿)。而200B版本的模型,则在多项基准测试中超过了Qwen、DeepSeek和Llama这三大开源模型家族中的旗舰模型。
快手Kwaipilot团队在技术报告中,揭秘了KAT-V1模型背后的多项技术创新。
该团队不仅提出了一种全新的长短思考混合模型训练范式,还基于传统强化学习算法(GRPO),提出了带有新型强化学习方法Step-SRPO,进一步提升了模型输出token的思考密度以及对是否应该开启思考模式的判断力。
在部分基准测试中,即使模型自我选择不开启思考模式,受益于融合训练方法和推理模板,性能也有小幅上涨。
KAT-V1模型家族的40B版本已在开源模型托管平台Hugging Face上线。技术报告透露,200B版本的MoE模型仍在训练过程中。同时,用户也可在快手打造的AI研发助手Kwaipilot中体验到这一模型。
模型开源地址:https://huggingface.co/Kwaipilot/KAT-V1-40B
技术报告地址:https://arxiv.org/pdf/2507.08297
自OpenAI推出o系列模型以来,通过工程设计和后训练技术,让模型在回答问题前进行更深入的思考、推理和规划,已经成为智能水平提升的重要路径。
然而,在实际体验中,推理模型“凡事都要先思考”的运行模式,演变成了“过度思考”的问题:模型机械地展开冗长的推理链,缺乏灵活的判断能力。
在问及简单事实性问题时,推理模型也会过度思考
推理模型的这种思考模式,其实与人类日常的思考模式大相径庭,人类往往先基于直觉或经验做出快速判断,再在需要时进行深入的思考。
“过度思考”现象不仅显著拉长了响应时间,让用户感到“笨重”、“迟钝”,还会在问及简单事实性问题时带来明显负面体验。对于需要快速、直接反馈的场景(如客服问答、代码调试),这种延迟会降低满意度和使用意愿。
同时,大模型“过度思考”还会显著增加推理所需的计算资源和能源消耗,导致运算成本上升。对面向C端的大规模部署来说,这种浪费尤为突出。
为了“显得在思考”,模型还有可能在中间步骤生成并不准确或逻辑矛盾的内容。这些内容若被用户误解为可靠推理,反而增加了错误决策的风险。
已经有不少模型厂商注意到了“过度思考”的挑战。谷歌为Gemini引入了思考预算组件,允许开发者选择模型的思考长度;Anthropic则将Claude 4模型做成了混合推理模型,用户无需切换模型,即可自主选择是否开启推理。
不过,上述流程仍需要人类的参与和配置。要更为系统性地解决推理模型的“过度思考”问题,研究者还需要探索如何让模型根据任务复杂度自主决定是否思考,实现更灵活、高效的人机协作。
快手Kwaipilot团队已在今年6月初发布了上述问题的初步解决方案——KwaiCoder-AutoThink-preview,虽然名字是Coder但具备通用模型能力,KAT-V1在其基础之上针对推理能力进行了重点优化。
KAT-V1模型由Qwen2.5-32B扩展而来,通过分层定向扩展的策略,将模型参数量有选择地扩展到40B,减少了无效的参数增长,实现规模与计算效率的平衡。
在KAT-V1模型的预训练阶段,Kwaipilot团队构造了大量的思考/非思考数据。对于非思考数据,为了保证问题的广泛性,他们从预先收集的5TB tokens预训练数据中,抽取出部分带有推理特征、具有一定难度的多领域数据。
思考数据则使用一个Agentic框架来合成。该框架由解答者(solver)、思考者(thinker)和评论者(critic)组成。解答者先提供初步答案,思考者对解决方案进行反思和迭代改进,评论者对整个流程进行监督,以保证逻辑一致性和输出质量。
这一框架可在一定程度上提升合成数据的质量——只有经过核验的高质量合成数据才能被保留,并转化为长思维链(long-CoT)数据。
预训练阶段,Kwaipilot团队使用了大约1000万个示例的语料,其中约34.8%的数据为思考数据,约65.2%的数据为非思考数据。这些数据涵盖了科学、代码、数学、工具调用和通用知识等广泛领域,给模型的能力泛化提供基础。
Kwaipilot团队选择通过模型蒸馏的方式完成模型的初始化冷启动——先让一个大型教师模型在输入数据上输出详细的概率分布,再让较小的学生模型在相同输入下产生预测,通过最小化两者之间的差异,使学生模型学习教师模型的预测模式和知识。
不过,KAT-V1采用了独特的异构蒸馏框架,能够更高效地将教师模型的知识传递给学生模型。该框架由通用Logits蒸馏损失(ULD Loss)和多Token预测(MTP)两大模块组成。
其中,MTP模块使学生模型在一次计算中不仅能预测下一个Token,还能同时预测多个后续Token,从而增强模型对“未来收益”的理解。通俗地说,多Token预测让模型学会做出有利于整个序列长远表现的决策,提高了预测的准确性和学习效率。
在多种对齐方式中(如对齐embedding层或语言模型输出等),Kwaipilot团队发现,对齐Token级别的logits效果最好,这就是通用Logits蒸馏损失(ULD Loss)的核心。
教师模型在生成每个Token(如Token A、B、C)时,会输出对应的logits(即模型预测该Token的原始分数),并将其作为监督信号传递给学生模型的MTP模块。ULD Loss则弥合了正常序列预测与并行预测之间的差异,使得即便模型架构不同,也能灵活实现知识迁移。
整体上,这个设计大大提高了知识迁移的效率,让小模型在冷启动时用较少算力就能快速获得较好的性能。Kwaipilot团队透露,他们以传统方法1/30的成本,完成了模型的冷启初始化。
在预训练阶段,模型已经通过思考、非思考数据的注入,学会了在得到外部指令时,被动切换思考模式。而后训练阶段的目标,则是让KAT-V1学会根据输入查询,自动确定适合的思考模式。
SFT for AutoThink
Kwaipilot团队通过结构化的数据合成流程,让模型学会在Think-on(思考)和Think-off(非思考)两种模式之间做出选择。每个查询先由多个模型投票决定适合的推理模式,再分别用DeepSeek-R1或DeepSeek-V3生成回答,确保内容多样且契合任务。
同时,为提升模型对思考模式的理解,每条样本还由DeepSeek-V3生成解释说明合理性,作为额外训练信号,并将约1%的数据随机分配模式防止过拟合。所有数据都使用统一模板,包含对是否需要推理的判断、(如需推理时的)推理过程及最终回答,使模型既能判断是否推理,又能清晰区分分析与作答。
这些数据让模型学会了如何判断用户意图以及问题难度,并决定如何思考后再进行回答。经过冷启 SFT,KAT-V1可以在需要思考的困难榜单上达到DeepSeek-R1-0528 95%以上的性能;在较为简单的榜单上,由于模型自我决定部分问题进行深度思考,而出现10%-30%的性能涨幅。
仅通过精细化数据 SFT 所获得的判断能力受到数据制约,其智能程度和灵活性仍然受限,泛化性也还不够强。
为了让模型的思考判断更加智能,Kwaipilot团队需要进行强化学习。最初,他们采用传统强化学习算法GRPO进行端到端强化学习,希望让模型更智能地判断是否需要思考。但由于GRPO缺乏清晰的过程监督,训练中出现了不稳定现象,比如模型表面上判断应开启思考模式,最终却不进行推理,或者在简单的代码和数学题上也频繁启动推理。
最终,Kwaipilot团队提出了一种分布式奖励的强化学习算法:Step-SRPO。在Step-SRPO框架中,模型先进行“推理必要性评估”,判断每个问题是否需要深入思考,以避免对简单问题浪费计算资源。
随后,通过双重奖励机制引导学习:判断奖励(Judge Reward)根据模型是否正确选择推理模式打分,鼓励准确判断推理需求;答案奖励(Answer Reward)依据最终回答的正确性和质量进行评分,并结合判断奖励进行调整,确保回答质量和推理选择相一致。
数据显示,由于强化学习的奖励策略,模型选择思考模式的比例不断降低。
模型在训练阶段,由于强化学习的奖励策略,模型开启think-on的比例不断降低
这种趋势在测试集上的表现更为明显,模型在多个测试集的平均token数下降了20%-30%,其中复杂推理榜单(例如AIME 2025/2024、LCB、GPQA) 变化趋势最小,但是相对简易榜单的比例下降趋势更为明显。
模型在测试集合,模型开启think-on的比例不断降低
Step-SRPO让模型在训练中逐步学会既能保持高准确性,也能根据问题难度灵活调整推理深度,最终实现在模型性能上涨的前提下,还能进一步降低token的使用,提升了模型输出token的思考密度以及对是否应该开启思考模式判断的智能程度。
强化学习训练后,KAT-V1 40B成功学会了自动在某些简单问题上切换到非思考模式,模型性能在保持和DeepSeek-R1-0528接近的水位下,平均token消耗降低。
约为 DeepSeek R1-0528 85%左右的token消耗量
经过专项训练后的模型,对于困难的问题会首先进行判断难易程度,然后进行思考并给出解题过程及最终步骤。
这里以前段时间较火的小球问题举例,让大模型写一个程序,模拟小球的运动。
"write a Python program that shows a ball bouncing inside a spinning hexagon. The ball should be affected by gravity and friction, and it must bounce off the rotating walls realistically" (编写一个Python程序,展示一个在旋转六边形内弹跳的小球。小球需受重力和摩擦力影响,并能够根据旋转的六边形墙壁实现真实碰撞反弹效果。)
对比O3-mini与DeepSeek-R1 生成的代码看起来也更流畅自然。
为了测试模型的多轮对话能力,我们给题目的难度再升升级,让模型能够模拟小球尾迹,并且当用户按下空格时,小球数量增加,并且希望模型可以正确处理小球之间的碰撞,再经过新一轮的对话后,模型写出了以下代码:
在代码生成方向,由于编程相关问题往往更加复杂,而这种 “pre-think” 的推理形态也展现出更强大的问题理解能力以及规划能力。
在复杂的SQL优化例子中,KAT-V1-40B自动启动其思考模式。在15秒的思考时间内,提供了结构化的多步骤分析,而另一款推理模型则需要53秒,KAT-V1-40B还给出了问题的分析和路径的规划,在深度、架构洞察力和可扩展性建议方面要优于另一款推理模型。
在处理不需要思考的问题时,最先进的推理模型仍然会进行不必要的逐步分析,生成近400个token的冗长回复,并产生额外的17秒延迟。
相比之下,KAT-V1-40B 正确地识别了任务的简单性,迅速激活了非思考模式,并生成了高质量的回复,这种特性进一步巩固了其在实际部署中的实用价值:
当前的思考模型相比非思考模型,往往在复杂场景不能很好的识别用户意图。而在这种场景下,由于这种“pre-think”的过程存在,往往能结合用户意图和问题进行更详细的方案设计与规划。
除了自主思考控制之外,KAT模型还支持用户通过简单的意图指令(例如显式的思考或非思考偏好)来引导模型是否开启思考模式:
KAT-V1的思考形态也适配了智能体模式,模型可以在多智能体的场景中,准确地在思考与非思考之间切换。例如,文件检查期间禁用推理,并在需要诊断或代码生成时主动启用深度推理和基于工具的探索。、
以下是一个模型和Kwaipilot产品中 智能体代码生成功能 协同作用的例子:
Kwaipilot团队在过去几个月里已开源多款覆盖推理、编程、Embedding等领域的模型。在后续的工作中,我们将详细介绍完整的AutoThink训练框架,并计划开源相关训练数据、强化学习代码库,以及1.5B、7B和13B等不同规模的模型。此外,AutoThink框架未来有望扩展到多模态和交互式智能体应用,进一步提升模型的可控性与通用性。KAT-V1的200B参数的MoE(Mixture-of-Experts)变体也有望在训练完成后向社区开放。
感谢大家关注Kwaipilot近期的工作,道阻且长,行则将至,我们会在大模型的探索之路上砥砺前行。